Market data: EWMA and GARCH(1,1) parameter estimation
- Compare the volatility of the ABB share obtained for the EWMA model
with a constant
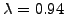 or a maximum likelihood estimate
of the parameter.
Identify regimes where the estimate may be above or below 0.94.
or a maximum likelihood estimate
of the parameter.
Identify regimes where the estimate may be above or below 0.94.
- Study the volatility obtained for the GARCH(1,1) model, checking whether
it is possible to define a long-term average, evaluate the impact
of recent events and tell how quickly they are forgotten.
- Which value of the volatility would you use to predict the financial
risk in the year following this sequence?
|


 ','..','$myPermit') ?>
SYLLABUS Previous: 1.5.2 Moving averages: UWMA,
Up: 1.5 Historical data and
Next: 1.6 Computer quiz
','..','$myPermit') ?>
SYLLABUS Previous: 1.5.2 Moving averages: UWMA,
Up: 1.5 Historical data and
Next: 1.6 Computer quiz
![$\displaystyle \mathrm{max}\prod_{i=1}^m \left[ \frac{1}{\sqrt{2\pi\nu_i}}\exp\l...
...}(\chi), \quad \chi=\sum_{i=1}^m \left[ \ln(\nu_i) +\frac{u_i^2}{\nu_i} \right]$](s1img107.gif)
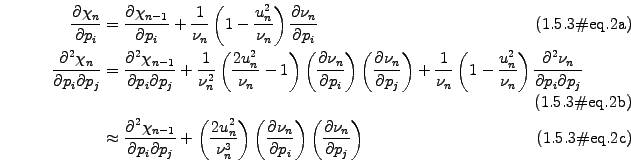
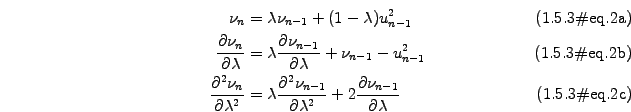
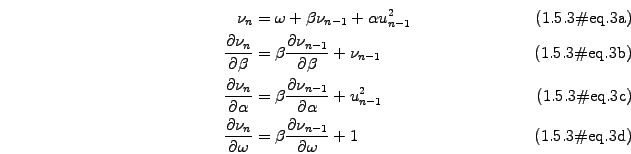
![$\displaystyle \bar{\sigma^2}=\frac{1}{N}\sum_{k=0}^N E[\sigma_{n+k}^2]$](s1img112.gif)